Event Timeout - A super powered event monitoring app for Seq

Table of Contents
"Something hasn't happened!"
My workplace has quite a number of disparate applications and scripts that drive critical SLAs. Historically, these were managed by exception and emailing errors to various mailboxes. This is a fairly poor approach to managing SLAs, since it is reliant on a human factor - someone has to see the email, understand its context, and action it.
If I send an email "SFTP Transfer failed" and don't provide enough information in the email for someone to consistently recognise what the service is, that's going to lead to confusion and a likely SLA breach. Similarly, while a team member who's been with the organisation might know the context, what if a new person picks up that email? What if that long-standing team member leaves and there's no-one to explain what it means? Did they document it? Prediction - we will probably get an SLA breach.
So it's been my task, and privilege, to design, implement, and drive adoption of a standard monitoring and alerting infrastructure. Seq and OpsGenie are central pieces of this infrastructure, allowing us to fully automate our critical monitoring and alerting process.
To accomplish this, we have had to mandate and drive Seq as our application logging server. I'm a big fan of Seq as a cost effective solution for structured logging, and the more application logs we integrate into it, the better we can monitor, troubleshoot, and debug problems.
There is a lot to consider with application logging, but for the purposes of this post, let's consider - how do we detect if an event has not happened in time?
Defining the problem
At its core, an application logging server is only as good as the logs it receives. It doesn't "know" anything inherently about what you're sending to it. It simply ingests your logs. Seq has some outstanding capabilities that certainly can help with this - for example, I could (and do) set a dashboard alert that can detect that no logs have been received in the past 15 minutes, and alert that there may be an outage. That's really useful ... but what if I need to look for a specific log event, and alert when I don't see it in time?
The answer is that we need to output a log event that we can react to, and we can do that with a Seq app.
Seq Apps
Seq has a fantastic ability to add Seq apps written by Datalust and the Seq community. Generally speaking, the approach lends itself to open source extension of Seq capabilities. Apps are installed via Nuget, and you can use your own private Nuget server for your own apps - but of course, making them available as a public Nuget feed benefits the community by making your enhancements available.
The Seq app approach is robust and well considered - you install an app, and can then configure as many instances of that app as you need, to meet your various purposes. For example, we make heavy use of the Json Archive app to create long term archives of various signals. The apps themselves use a small amount of RAM within the Seq instance.
In terms of my problem - there certainly were apps for timeouts such as Seq.App.EventTimeout and Seq.App.DeadMansSwitch. These are "tick/tock" handlers, which essentially arm and disarm based on incoming events. They don't get very specific about which events and when. However, they do output events to Seq when a timeout occurs - that, at least, is what we needed to do.
Requirements
I had a clear set of requirements in my head for a timeout app.
- Monitor for specific events by using a partial string match against @Message text (the rendered log message in Seq)
- Watch between a configurable start and end time
- Configurable timeout before a timeout log event is raised
- Configurable suppression interval before another timeout log event can be raised
- Allow days of week to be specified, so (for example) events that don't occur on weekends won't raise an alert
- Configurable alert message and description
- Configurable alert level - Verbose, Debug, Information, Warning, Error, or Fatal
- Add tags that can be used in alerting
All of this could be readily implemented with the Seq.Apps API, and I started my journey in creating a Seq app from scratch.
Along the way, I added some bonus goals as a result of further analysis and testing; teasing out additional requirements that enhanced our capabilities.
- Allow up to 4 properties to be configured and matched. Since Seq has excellent structured logging properties, I wanted to be able to react to more than just the @Message text. Essentially - if a property exists for a given event, I wanted to be able to evaluate it. This means that I can get really specific in what I'm matching for timeouts.
- Include/exclude days of the month (1-31), and day expressions (eg. first/last for first or last day of month, first weekday/lastweekday, first/second/third/fourth/fifth/last DayOfWeek). This is powerful when you need to (for example) have different timeouts between end of month and the rest of the month, or when events only ever occur on specific days.
- Repeatable timeouts. Initially I only ever allowed one positive match, and if that occurred, no further timeouts could happen in the interval. If you wanted a 'heartbeat' type of timeout - say looking for any event within 10 minutes, or an alert would be raised - you could accomplish this with a dashboard alert, but not Event Timeout.
- Extensive diagnostic logging (if enabled). Time-based event logging can make it complex to understand what happened and when - why didn't a timeout occur on this day? Diagnostic logging makes this much clearer, and in fact I use this on all instances and setup a signal for it - we can see our whole critical process monitoring just by looking in this signal.
- Public holiday automation. We have some processes that don't run on public holidays. We need to detect that, but having this as a manual configuration would be painful as a BAU process - so why not consume a public API like Abstract API Holidays? In fact, once I added this, it exposed a misconfiguration in one of our processes - Event Timeout knew that a given day was not a public holiday, but the process thought it was and didn't execute; Event Timeout raised the alarm and we were able to fix it before an SLA breach occurred.
Seq.App.EventTimeout
The result is an app that I imaginatively called Event Timeout ... because that's what it does. You can install it in your Seq instance by specifying the package id, Seq.App.EventTimeout.
It is a monster of an app that now underscores a majority of critical SLAs. If a process doesn't execute in the specified time, it raises an Error log event. We create signals around that, based on the well-defined properties such as AppName, and which apps such as Seq.App.OpsGenie can monitor and alert on. Some of the features that I added to Event Timeout drove me to add enhancements to this app as well, which made our alerting picture even more comprehensive.
When I say it's a monster of an app - it really is. I wouldn't be surprised to find that it has the most configuration items of any Seq app. In part, this is because of the multiple property match - Seq.Apps doesn't allow configuration of a Dictionary, which would be a useful way to express a config like this - simply provide a dynamic table with key and value expressions. I'd certainly put that as a "nice to have".
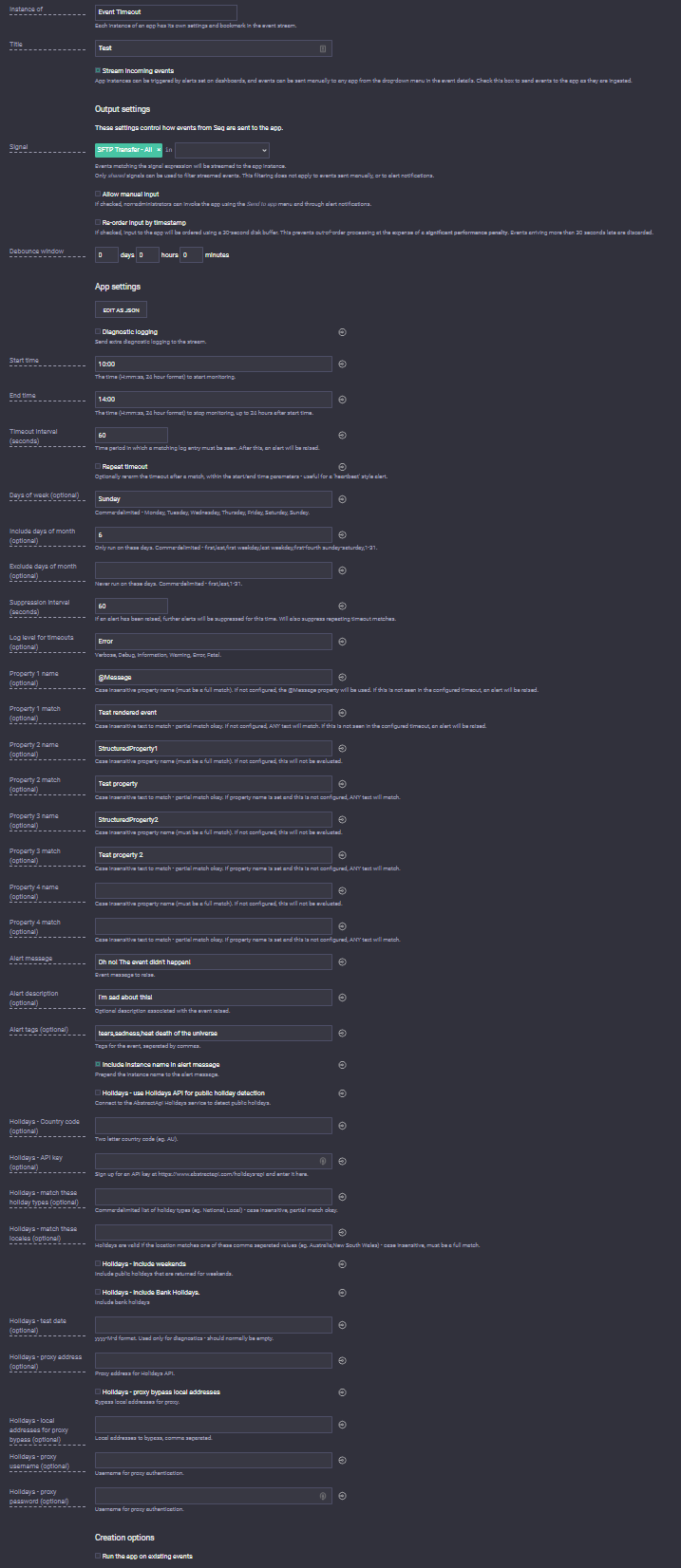
I've put example configs in the Event Timeout repository's readme, but below is what a config looks like.
This config would look for events occurring between 10am and 2pm on a Sunday, if the day of month is the 6th, and output an error every 60 seconds if an event matching:
- @Message contains "Test rendered event" AND
- StructuredProperty1 contains "Test property" AND
- StructuredProperty2 contains "Test property 2"
This is really specific, which makes the likelihood of a false positive very low. And that's the power of Event Timeout. I can use the properties from my apps that send to Seq, or an input like Seq.Input.MSSql that exposes multiple columns as properties, to make a positive match in a given timeframe, or raise a timeout alert.
The result
Event Timeout is forward looking and uses UTC time internally to calculate the "next" start event. So while writing this, I created the above instance and set the start time to 1 minute in the future - making sure to enable diagnostic logging so I could show you the 'magic' behind the scenes.
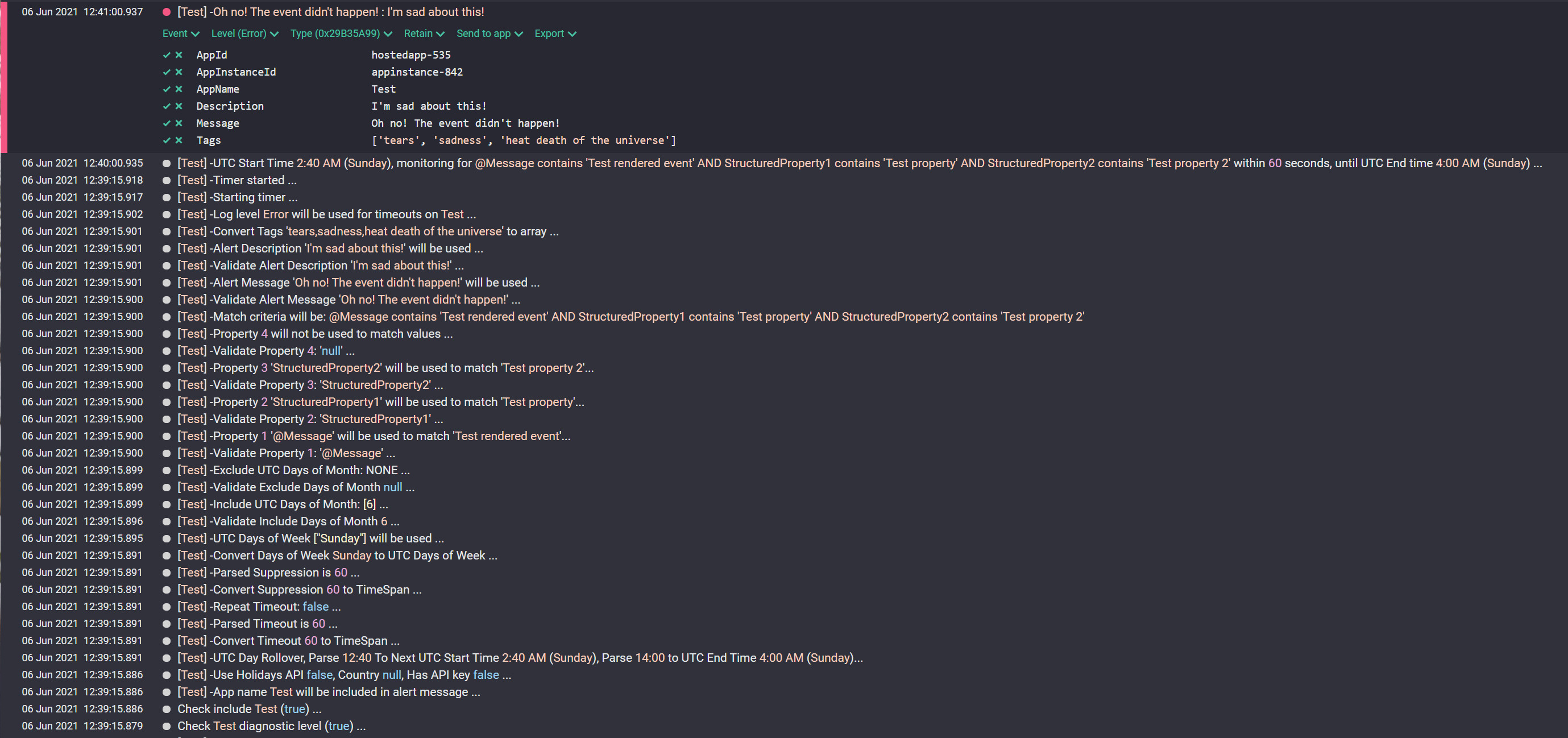
In short - we wind up with a usable Error. I've expanded the error event to show the properties - you can readily create a signal on the AppInstanceId or AppName, or the AppId if you want all instances. From there - it's just up to an app that monitors signals and sends it somewhere useful. We've used OpsGenie, Jira, Email+, and Teams alerts for various reasons.
It works. It gets people out of bed when they need to attend to a problem ... and the specificity of the configurations means that the alerts are always correct.
Public Holidays
You might note that I didn't configure the test instance with the Holidays API, because I didn't need it for that. Below is a sample of a configuration for the API that we actually use.
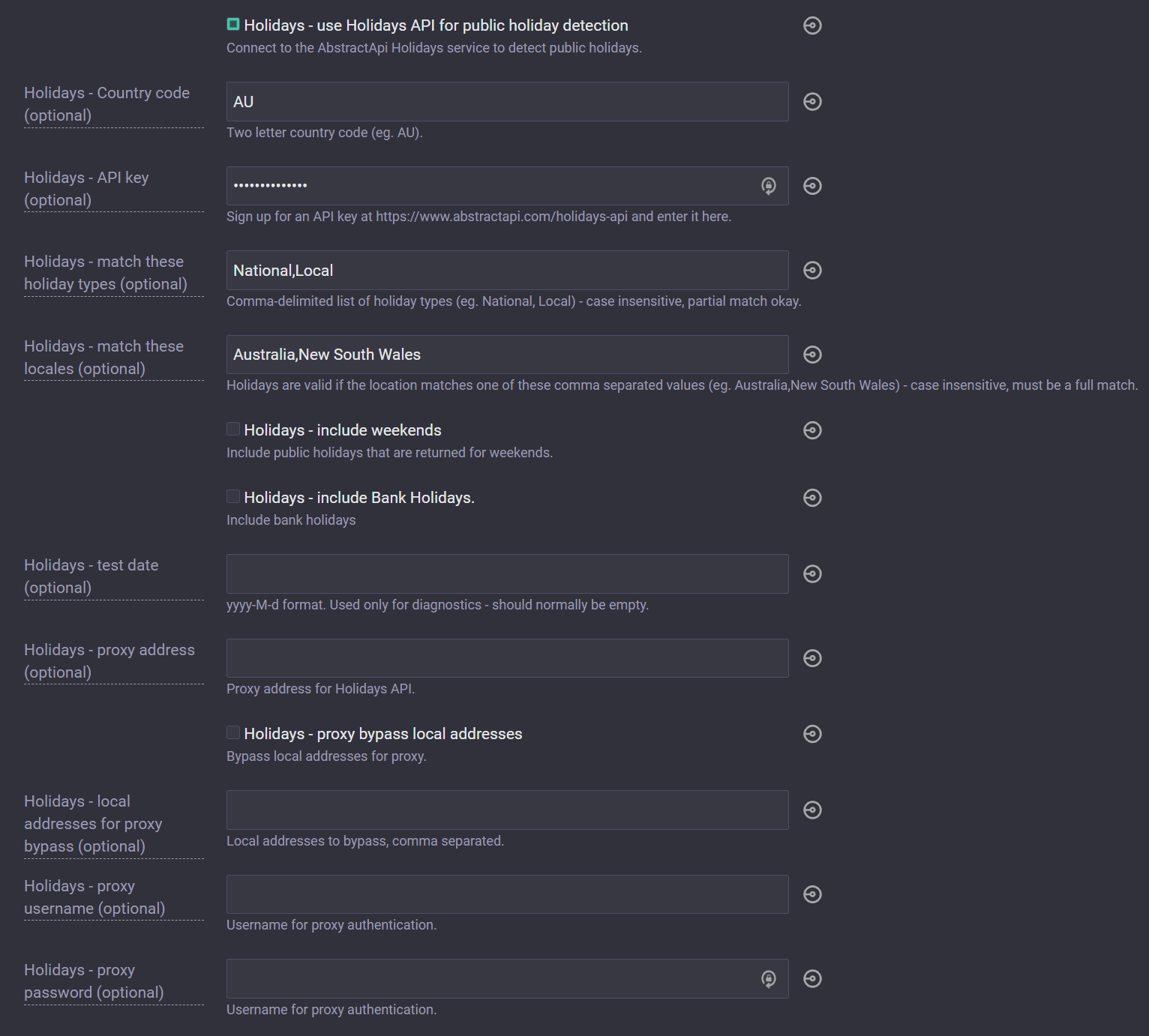
This is really powerful when a process doesn't run on public holidays - we do have a few - or when an alert simply doesn't need to be raised on those days.
Using AbstractAPI Holidays makes it easy. I use Flurl.Http for retrieving and parsing the Json feed - it's not essential, but I've used the library for a long time and I like the implementation.
While I absolutely support AbstractAPI's model, which is generous, and absolutely recommend subscribing to their paid plans - I wanted to be sure not to lock anyone in to a subscription to benefit from this feature. The intent isn't to cheat AbstractAPI out of money, but I needed to be able to provide an API while giving people choice. At the very least, it's a chance to evaluate their API before committing to subscription.
The free tier provides 1000 requests per month, and 1 request per second. There are some restrictions on the free plan - for example, you can only query the current year - but it does perfectly match our needs. In fact, the only "problem" is the 1 request per second limitation.
We can ensure that we stay within the 1000 request per month - simply by only checking for public holidays once per day, per instance. That's easy, and unless you have a huge number of Event Timeout instances, you'll stay under that limit.
If you configure multiple instances of Event Timeout with public holiday detection, though, you would likely run afoul of the 1 request per second. I accounted for that by allowing for a retry. If an error occurs when using the free plan, it's most likely that this is the API requests per second limit being reached, so we retry up to 10 times with a 10 second delay between each attempt.
That works, and works well, and means we have a fairly robust effort to ensure that public holidays are evaluated. We could still hit a limit, for example if there's more than 10 instances. We could make this yet another configurable item quite easily, but a reasonable limit of 10 seemed appropriate (and perhaps encouraging people to give AbstractAPI money! 😀)
While Event Timeout uses UTC timing internally, we handle the retrieval of public holidays as a local datetime - at midnight, retrieve today's public holiday list, and filter it based on the holiday type and locale settings. If we're currently in the middle of a "showtime" - the time between a start and end time - it will be retrieved when that showtime has ended. As noted, Event Timeout is forward looking, so we only evaluate public holidays against the next start time.
In Conclusion - Get Event Timeout for Seq!
There's a lot of thought and effort behind Event Timeout, and I'm quite proud of how it turned out. It certainly meets our specific needs, and if a problem is defined, we can readily map its existing features to the solution. I certainly hope that others can make use of it too!



Comments